 ♠️♥️♦️♣️ Play Hearts against a superhuman AI ♣️♦️♥️♠️
♠️♥️♦️♣️ Play Hearts against a superhuman AI ♣️♦️♥️♠️
Overview
The card game Hearts is difficult for a computer to master because it has a large game tree with elements of chance and uncertainty. Deep Counterfactual Regret Minimization (Deep CFR) is an algorithm designed specifically to tackle such games. We use a simplified version of Deep CFR to train an AI that plays Hearts at a superhuman level!
Background
Perfect information games
Games like Tic-Tac-Toe and Chess are called “perfect information” games because each player knows all relevant information about the state of the game. Nothing is hidden from the players in such games.
Playing Tic-Tac-Toe well is much easier than playing Chess well, though, because Chess has a much larger “game tree” of possible moves. An AI that plays Tic-Tac-Toe perfectly can be written in a few lines of code, but a program that plays Chess well is much more difficult to create. In recent years, great progress towards this goal has been achieved by deep learning programs like AlphaZero, which mastered Chess by playing against itself for a few hours.
Imperfect information games
AlphaZero doesn’t do as well with “imperfect information” games like Rock-Paper-Scissors (RPS) or Poker, however. In these games, some information is hidden from the players,1 which introduces a role for chance in the game. A beginner Poker player can sometimes beat an expert, depending on the luck of the draw. Card games typically have imperfect information, because players have “hands” that they keep private. Bridge is another example of such a card game.
In imperfect information games, a good strategy sometimes involves a degree of randomness. For example, the best strategy in RPS is to choose your hand shapes randomly. Bluffing in Poker is another example of strategic random behavior. Over time, a Poker player who never bluffs isn’t going to win as much as a player who bluffs well at the right time.
A strategy is called a “Nash equilibrium” if (roughly speaking) there is no other strategy that can beat it over the long run. However, such a strategy doesn’t do anything to exploit weaknesses that might exist in other strategies. For example, the Nash equilibrium in RPS is to play randomly, but against a player who always chooses Rock, an even better strategy is to always choose Paper. An imperfect information game might have multiple Nash equilibria, rather than a single best strategy.
We have to rethink the idea of a game tree for imperfect information games, since multiple game states might be indistinguishable to a player, given their imperfect knowledge (e.g. they don’t know the cards in other players’ hands). Instead, we consider a graph where each node represents all of the active player’s information about the state of the game when it is their turn to play. Each such node contains one or more distinct game states (from the point of view of an omniscient observer) and is called an “information set”.
Counterfactual regret minimization
As with perfect information games, imperfect information games can have a small number of information sets (e.g. RPS) or a large number (e.g. Bridge). There’s a powerful machine learning technique for solving imperfect information games called Counterfactual Regret Minimization (CFR), but it is only practical for fairly small imperfect information games, because it must visit each information set many times as it iterates to a good strategy.
CFR works by minimizing “counterfactual regret” at each information set. Regret is a confusing concept (at least to me), so I prefer to think of this as maximizing the value (aka “utility” or “advantage”) of each node instead. Roughly speaking, the idea is to start with a random strategy and then refine it so that actions with high value are favored. In this way, CFR “learns” how to play well over time.
However, due to the nature of imperfect information games, we have to be careful about evolving strategies that chase their own tail. For example, in RPS, CFR might start off with a bias towards Rock due purely to random accident. In the next iteration, it would learn to play Paper more often in response. Then in the next iteration, it would learn to play Scissors in order to take advantage of the bias towards Paper, and so on. In order to mitigate this problem, CFR takes the average of all strategies at the end of the run, rather than keeping just whatever the last strategy happened to be. Over many iterations of RPS, CFR finds that the average value of Rock, Paper, and Scissors are all ⅓, which gives us the best strategy. It is only this average over time that is guaranteed to converge to a Nash equilibrium. Visually, we can think of CFR as circling endlessly around this average strategy, rather than necessarily landing right on it.
Deep CFR
CFR keeps a table of regrets and strategies for each information set. This quickly becomes untenable for many games, due to the exponential explosion of game tree sizes. For example, Bridge has at least 1050 information sets, which is far too large to track individually.
To address this problem, Deep Counterfactual Regret Minimization (Deep CFR) uses a deep neural network to approximate the table instead. The input to the network is an information set, and the output is the network’s estimation of the value of each legal action in that information set.
The basic idea is:
- Start with a model for each player that plays randomly.
- Generate sample data by playing the current models against each other for many games. At various decision points within these games, compute the value of each legal action by comparing the predicted outcome of the action to the actual outcome of taking that action.
- Train new versions of the models using the comparisons generated in the previous step, along with comparisons generated by earlier iterations. (If the amount of training data becomes too large, use “reservoir sampling” to prune it.)
- Repeat from step 2 for multiple iterations.
As with vanilla CFR, however, the strategy learned by this process is not guaranteed to converge on a Nash equilibrium. Instead, we need to train a final network for each player at the end of the run that approximates the average strategy across all iterations.
Deep CFR is designed to work specifically for two-player zero-sum games. Each player requires a separate model, because they might use different strategies depending on their role (e.g. seat order). Deep CFR has been used successfully to master complex imperfect information games, such as a popular Poker variant called Texas Hold’em. And now, Hearts as well!
Hearts and Deep CFR
To my knowledge, there have been few attempts to create strong Hearts-playing programs, and most of those that do exist are based on heuristic rules, rather than rigorous algorithmic techniques. The website Trickster, for example, has written such a program, but it does not play Hearts at a high level. My father, Gerald Berns, also created a heuristic program called Killer Hearts that was, I believe, the best Hearts program in existence prior to this project.
“Shooting the moon” makes Hearts particularly difficult to master for both computers and humans. A good Hearts player cannot focus on just minimizing points taken. They must also be able to shoot the moon when possible, and try to prevent other players from shooting the moon. Balancing these goals requires a great deal of acumen.
Although Hearts is neither a two-player nor a zero-sum game, this project serves as a demonstration that it is nonetheless still a good candidate for Deep CFR, with some adaptations.
Simplifying Deep CFR
Several simplifications to Deep CFR are possible when applying it to Hearts:
- Since Hearts strategy is the same for all players, there is no need to train a separate model for each player. Instead, all players can share the same model.
- Because misdirection and bluffing are not a major part of Hearts strategy, the “tail chasing” behavior of CFR described above is not a concern. Empirical results show that the strategy network converges directly on an approximate Nash equilibrium after fewer than ten iterations. There is no need to train a separate network on the average strategy.2
- For the same reason, training data from earlier iterations is less important for keeping the strategy evolution “on track” to a Nash equilibrium. Instead of reservoir sampling, we can train the next iteration using data generated only by recent iterations.3 This can speed up the training phase considerably.
Adapting Hearts
Zero-sum, two-player game
There are 26 points in each Hearts deal: one point for each Heart card, and thirteen points for the Queen of Spades. To convert Hearts to a zero-sum game, we define a payoff function that subtracts each player’s score from the average score of the other players. This ensures that the sum of all payoffs is always zero. For example:
| Seat | Points | Payoff |
|---|---|---|
| West | 2 | 6 |
| North | 5 | 2 |
| East | 0 | 8⅔ |
| South | 19 | -16⅔ |
| Sum | 26 | 0 |
Note that the sign of the payoff is reversed so that taking more points results in a lower payoff. Taking seven or more points in a (non-shoot) deal results in a negative payoff for that player, because the average number of points taken per player is 26/4 = 6½. Shooting the moon has a payoff of 26 points, regardless of whether points are subtracted from the shooter’s score or added to the other players’ scores. The other players each receive a payoff of -8⅔, which is one third of -26.
Using this payoff function, Hearts can be seen as a cutthroat two-player game in which each player is simply trying to maximize their own payoff versus the combined payoff of the other players. It’s “me vs. the world”.
Non-cooperation
Because a game of Hearts ends only when one of the players reaches 100 points, it can sometimes benefit players to cooperate near the end of a game in order to avoid going over the limit. For example, if South is the current low-scorer, and North is near 100 points, East might try to make South take the Queen of Spades instead of giving it to North, which would end the game.
Modeling this correctly requires a separate game-level payoff function that is not explicitly defined by the rules of Hearts. For example, is it better to play it safe and finish in second place rather than take a big risk and finish last? If two players tie for first place at the end of a game, does this dilute their accomplishments? One simple answer is to reward one point to each winning player (including ties) and no points to the other players. This is the approach taken by Killer Hearts. Note that this results in an aggregate win rate of more than 100% due to ties.
In contrast, this project currently ignores the game-level payoff entirely, and focuses only on the score within the current deal. Like the fabled scorpion, players never cooperate, even when it means their own destruction. This approach is nonetheless still good enough to dominate game-aware heuristic players, like Killer Hearts, over the course of a full game.4
Design
Card exchange
At beginning of every non-Hold deal, each player must pass three cards to another player. I chose to model this exchange as twelve separate actions (four players × three cards each), each of which represents passing a single card. This made it easier to unify card passing and card playing in a single neural network, since the output of the network is always a single card. The actual order of these card passes is not specified by the rules of Hearts and does not matter as long as players are not privy to any incoming passed cards until they have finished choosing all three outgoing cards.
Information set
An information set contains all information known to a player about the game state, including information known only to that player. Specifically, a Hearts information set contains the following information about the deal:
- The dealer’s seat.
- The current player’s seat (West, North, East, or South).
- The current player’s hand.
- Card exchange details:
- The direction of the pass (Left, Right, Across, or Hold).
- The set of cards passed by the current player so far, if any.
- The set of cards passed to the current player, if the exchange is over.
- The set of cards played so far (and which players played them), organized chronologically into tricks.
From an information set, one can deduce:
- Whether Hearts have been broken.
- Which players are known to be void in which suits.
- The number of points taken so far by each player in the deal.
- The set of unplayed cards.
- The set of legal actions available to the current player.
Neural network
Logically, a strategy model is a neural network that takes an information set as input and produces the value of each possible action as output. Implementing this physically required major design choices.
Input encoding
An information set is encoded into a vector of Boolean flags, laid out linearly as follows:
| Data | Size | Description |
|---|---|---|
| Current player’s hand | 52 | Multi-hot vector in the deck size, with no more than 13 hot values |
| Exchange direction | 4 | One-hot vector in the number of exchange directions (Left, Right, Across, Hold) |
| Outgoing pass | 52 | Multi-hot vector in the deck size, with no more than three hot values |
| Incoming pass | 52 | Multi-hot vector in the deck size, with either exactly zero or exactly three hot values |
| Cards previously played by each player | 208 | A multi-hot vector in the deck size for each of the four players, starting with the current player. Each vector will have no more than 13 hot values. |
| Current trick | 156 | A multi-hot vector in the deck size for each card played so far in the current trick. The maximum number of cards already played in an active trick is three, so zero-hot placeholders are used to pad out shorter tricks. |
| Known voids | 12 | A multi-hot vector in the number of suits times the number of other players |
| Deal score | 4 | A multi-hot vector in the number of seats. This simply encodes whether each player has taken any points, but not how many points each player has taken. This is crucial for determining which players can shoot the moon. |
| Sum | 540 |
Note that some information is lost in this encoding, such as the order of cards played in previous tricks. In game theory terms, this means that we now have “imperfect recall” of past actions. Technically, Deep CFR is not guaranteed to converge for such a representation, but this small degree of abstraction does not present a hindrance to success in practice.
Output encoding
Outputs are encoded as a vector of 52 floating point numbers, representing the value (aka regret, utility, advantage) of passing/playing each card in the deck.
To convert this output to a strategy, illegal actions are ignored, and the remaining values are normalized to sum to 1.0 (“regret matching”). An action can then be chosen by sampling this probability vector non-deterministically.5
Structure
The architecture of the neural network is relatively straightforward, consisting of a fully-connected input layer, some number of repeated hidden layers, and a fully-connected output layer. Someone with more deep learning ability than me might be able to come up with a better design, but this one worked quite well in practice.

(Original diagram created by Gemini, with my edits.)
In practice, I found that a hidden size of 1080 (twice the input size) with four hidden layers worked well. I was surprised that a model this small could master Hearts, but adding more layers or features proved fruitless.
Implementation
My background is in software development, not game theory or machine learning, so I had a significant amount to learn while working on this project. There were many wrong turns and failed experiments that are not described here.
Programming language
F# is my preferred programming language and I chose to use it for the implementation. As a functional programming language, F# is well-suited for the generation of sample data, which is essentially a black box that takes the current strategy model as input and emits sample data generated by playing that model against itself. Training the next iteration of the strategy model from that sample data was a bit more of a reach in F#, but fortunately I found TorchSharp to be an adequate .NET stand-in for PyTorch.6 I was even able to write the Hearts web application’s user interface in F# by compiling it to browser-friendly JavaScript using Fable. This allowed the app client and server to share the same core Hearts library code and communicate seamlessly over the web.
Code organization
The major F# projects in this solution are organized as follows:
Core Hearts logic
-
PlayingCards.fsproj: A library that provides general support for playing cards, but is not specific to Hearts. This is intended to be reusable for other card games. -
Hearts.fsproj: A library that implements the basic rules of Hearts. It provides aClosedDealtype that represents the public, shared information in a deal, and an omniscientOpenDealtype that adds in all private information, such as each player’s hand.7 It also provides anInformationSettype that gathers all information known to a player about a deal and aTournamentmodule for running a 2v2 tournament between two players (with duplicate deals for fairness).
Deep learning
-
Hearts.Model.fsproj: A library that defines the neural network and encoding. Hearts.Learn.fsproj: A library that provides shared Deep CFR support for both generating sample data and training new models. AnAdvantageSampleconsists of:- An encoded information set.
- A 52-vector of observed regrets for that information set. (Illegal actions will have a zero value.)
- Iteration number, which is used for weighting the sample. Later iterations are given a greater weight.
This library also defines a binary file format for storing large numbers of advantage samples. These “sample stores” have a
.binfile extension.-
Hearts.Generate.fsproj: An executable for generating new samples from an existing model. This traverses many game trees in parallel, generating samples at a relatively small number of decision points within each game. (The game tree is far too large to generate a sample at each node.) Nodes closer to the root have a greater chance of being sampled (via a “decay function”) because there are fewer of them.Multi-threaded batch inference in the traversal of these deals is crucial to performance and was probably the most technically difficult code to write in the entire project.
This executable can be run simultaneously across multiple machines (each with a copy of the same model) in order to generate samples more rapidly. The resulting sample stores can then be aggregated for training in the next step.
Hearts.Train.fsproj: An executable for training a new model from existing samples. After each epoch, the state of the model is saved in a PyTorch.ptfile. For example,AdvantageModel-i005-e023.ptis the model from the 23rd epoch of the 5th iteration. Training cannot currently be distributed over multiple machines.
The basic process is to alternate running Hearts.Generate and Hearts.Train for multiple iterations.
Web application
Hearts.Web.Server.fsproj: A Suave web part that exposes an API for playing against a trained Hearts model:GetActionIndex: A function that maps a given information set to a single action. This is used to implement the computer players.GetStrategy: A function that maps a given information set to a strategy vector. This can be used to provide the user with a hint about what to play next.
-
Hearts.Web.Harness.fsproj: A console program that hosts the Suave web part in a simple web server for development, debugging, and testing. Hearts.Web.Client.fsproj: An F# Fable user interface for playing Hearts in a web browser.8
Results
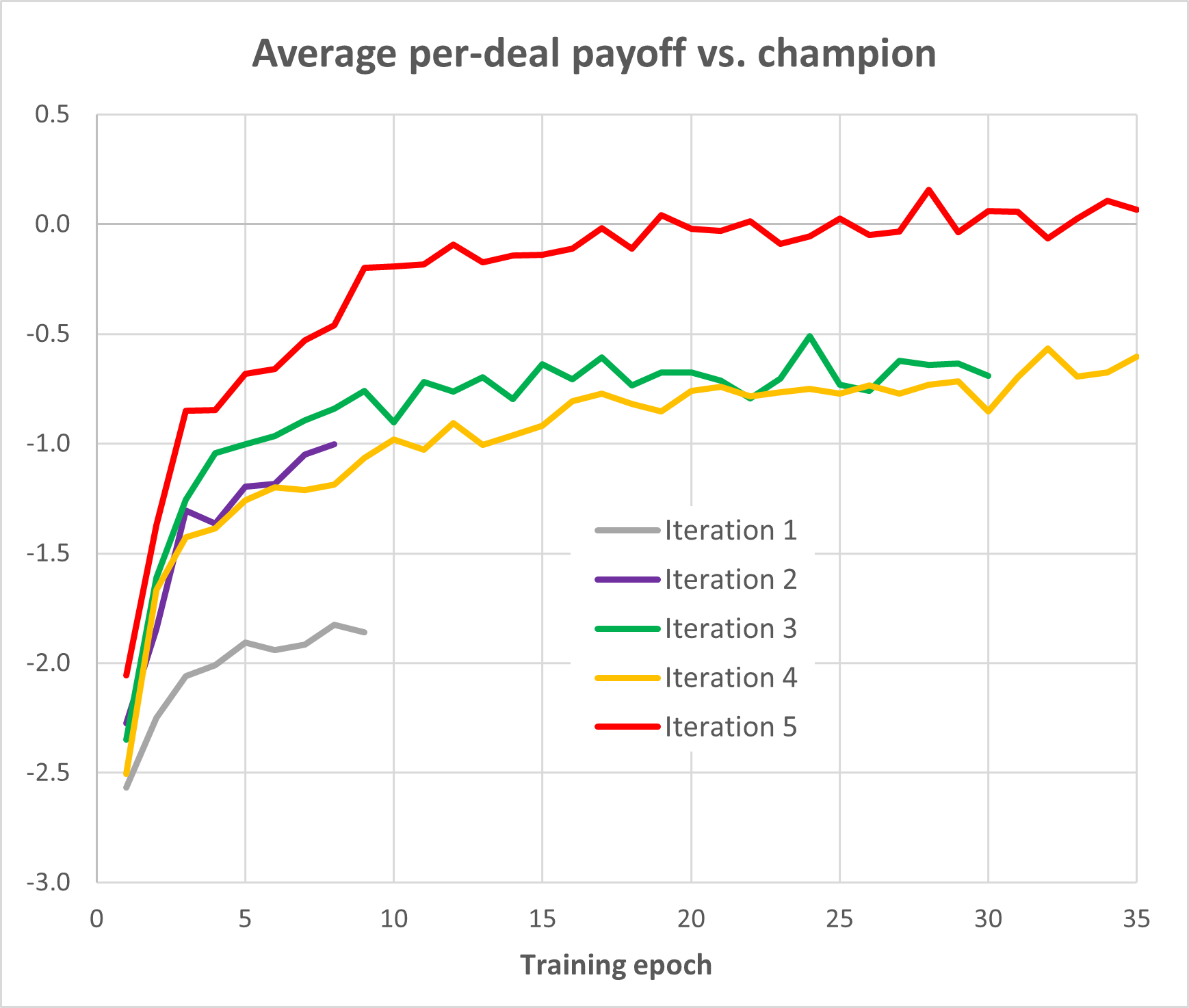
This graph was generated retrospectively by choosing the best player from Iteration 5 (AdvantageModel-i005-e027.pt) and running each of the checkpoint models against it.
Training details
One of the few constants I encountered in training a Hearts model is that more sample data produces better results. For each iteration, I aimed to traverse about 100,000 deals, producing about 1,000 samples per deal, for a total of approximately 100,000,000 samples per iteration. This is a large amount of data, amounting to about 100 GB of packed binary files over five iterations. The entire process took several days, running mostly on my desktop computer (Intel i9-12900 CPU with a NVIDIA GeForce RTX 3070 GPU), with minor assistance from an old laptop and a Vast.ai instance for sample generation.
-
Iteration 1: I generated approximately 200,000,000 samples from a random player. Since no neural network inference was involved, this is much faster than sample generation in subsequent iterations. A model was then trained on all the samples. It’s remarkable that a fairly strong Hearts player can be created just from a large amount of random play data.
-
Iteration 2: I generated approximately 100,000,000 more samples from the best Iteration 1 model and trained a new model from those samples plus ~100,000,000 of the Iteration 1 samples.
-
Iteration 3: I generated ~80,000,000 samples from the best Iteration 2 model and trained a new model from those new samples plus ~80,000,000 of the Iteration 1 samples. No samples from Iteration 2 were used. My thinking at the time was that using Iteration 1 samples would be better at keeping training “on track”, but I’m no longer confident that this is true.
-
Iteration 4: I generated ~90,000,000 samples from the best Iteration 3 model and again trained a new model from those plus ~80,000,000 of the Iteration 1 samples. The graph above implies that the resulting model was a no better than the previous iteration’s result, but I was not aware of this at the time.
-
Iteration 5: I generated ~120,000,000 new samples from the best Iteration 4 model and trained a new model from those plus about 90,000,000 samples from Iteration 4. This seemed to produce a much stronger player than re-using Iteration 1 samples again.
I stopped at this point, but it’s entirely possible that another iteration would produce an even stronger player. There’s no way to know how close we are to an actual Nash equilibrium.
Authorship
Except where noted, all source code and documentation in this project was written by me (not by generative AI).
Footnotes
-
I think “hidden information” would have been a better name for these types of games. “Incomplete information” might have also been a good name, but that actually means something completely different. Game theory is confusing sometimes. ↩
-
In the terminology of Deep CFR, the “advantage model” and the “strategy model” are the same thing for this Hearts project. ↩
-
In fact, it might be possible to use only training data from the most recent iteration, but I haven’t proven this yet. ↩
-
As of this writing, the Deep CFR technique produces a player that wins about 58.0% of games vs. 43.7% for Killer Hearts in a set of 10,000 two-against-two games. Since Killer Hearts plays at the level of an expert human, this result is the basis of my claim that the Deep CFR player is superhuman. (Plus, anecdotally, I’ve not been able to win a single game against it myself.) ↩
-
Non-determinism is important for games of deception, like RPS and Poker, but probably not crucial for Hearts. One might instead always choose the card with the highest value, although I have not investigated this possibility much. Note that, in Hearts, a group of cards might be logically equivalent in a given information set, so perhaps their total value should be used as the decision basis, rather than their individual values. ↩
-
I really dislike Python, but PyTorch is king. ↩
-
The
OpenDealtype is necessary for managing an actual game of Hearts, but it would be cheating to use this type in the implementation of a Hearts player, so the API makes it impossible. ↩ -
Disclaimer: I am not much of a front-end developer, but I tried my best. JQuery is hard. ↩